
Another Quora question that I answered recently: What is the difference between Data Analytics, Data Analysis, Data Mining, Data Science, Machine Learning, and Big Data? and I felt it deserved a more business like description because the question showed enough confusion. This is pretty understandable given the amount of hype out there and all the different messaging from vendors, consultants and analysts.
First things first, doing stuff with data, whatever you want to call it is going to require some investment – fortunately the entry price has come right down and you can do pretty much all of this at home with a reasonably priced machine and online access to a host of free or purchased resources. Commercial organizations have realized that there is huge value hiding in the data and are employing the techniques you ask about to realize that value. Ultimately what all of this work produces is insights, things that you may not have known otherwise. Insights are the items of information that cause a change in behavior.
Let’s begin with a real world example, looking at a farm that is growing strawberries (here’s a simple backgrounder The Secret Life Of California’s World-Class Strawberries, this High-Tech Greenhouse Yields Winter Strawberries , and this Growing Strawberry Plants Commercially)
What would a farmer need to consider if they are growing strawberries? The farmer will be selecting the types of plants, fertilizers, pesticides. Also looking at machinery, transportation, storage and labor. Weather, water supply and pestlience are also likely concerns. Ultimately the farmer is also investigating the market price so supply and demand and timing of the harvest (which will determine the dates to prepare the soil, to plant, to thin out the crop, to nurture and to harvest) are also concerns.
So the objective of all the data work is to create insights that will help the farmer make a set of decisions that will optimize their commercial growing operation.
Let’s think about the data available to the farmer, here’s a simplified breakdown:
1. Historic weather patterns
2. Plant breeding data and productivity for each strain
3. Fertilizer specifications
4. Pesticide specifications
5. Soil productivity data
6. Pest cycle data
7. Machinery cost, reliability, fault and cost data
8. Water supply data
9. Historic supply and demand data
10. Market spot price and futures data
Now to explain the definitions in context (with some made-up insights, so if you’re a strawberry farmer, this might not be the best set of examples):
Big Data
Using all of the data available to provide new insights to a problem. Traditionally the farmer may have made their decisions based on only a few of the available data points, for example selecting the breeds of strawberries that had the highest yield for their soil and water table. The Big Data approach may show that the market price slightly earlier in the season is a lot higher and local weather patterns are such that a new breed variation of strawberry would do well. So the insight would be switching to a new breed would allow the farmer to take advantage of a higher prices earlier in the season, and the cost of labor, storage and transportation at that time would be slightly lower. There’s another thing you might hear in the Big Data marketing hype: Volume, Velocity, Variety, Veracity – so there is a huge amount of data here, a lot of data is being generated each minute (so weather patterns, stock prices and machine sensors), and the data is liable to change at any time (e.g. a new source of social media data that is a great predictor for consumer demand),
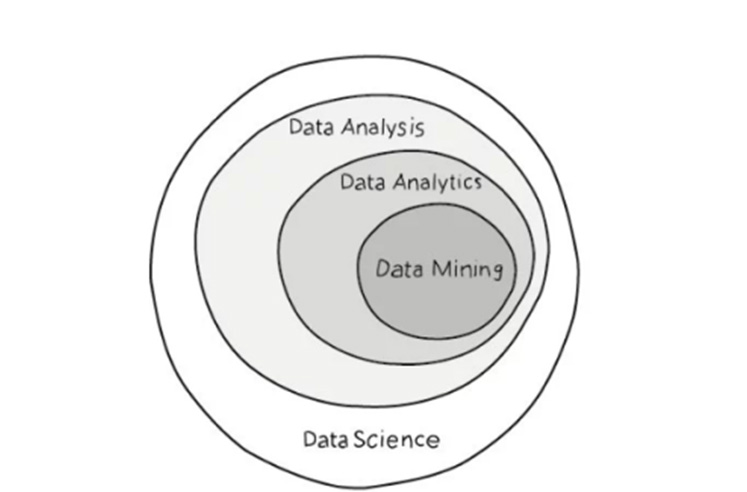
Data Analysis
Analysis is really a heuristic activity, where scanning through all the data the analyst gains some insight. Looking at a single data set – say the one on machine reliability, I might be able to say that certain machines are expensive to purchase but have fewer general operational faults leading to less downtime and lower maintenance costs. There are other cheaper machines that are more costly in the long run. The farmer might not have enough working capital to afford the expensive machine and they would have to decide whether to purchase the cheaper machine and incurr the additional maintenance costs and risk the downtime or to borrow money with the interest payment, to afford the expensive machine.
Data Analytics
Analytics is about applying a mechanical or algorithmic process to derive the insights for example running through various data sets looking for meaningful correlations between them. Looking at the weather data and pest data we see that there is a high correlation of a certain type of fungus when the humidity level reaches a certain point. The future weather projections for the next few months (during planting season) predict a low humidity level and therefore lowered risk of that fungus. For the farmer this might mean being able to plant a certain type of strawberry, higher yeild, higher market price and not needing to purchase a certain fungicide.
Data Mining
This term was most widely used in the late 90’s and early 00’s when a business consolidated all of its data into an Enterprise Data Warehouse. All of that data was brought together to discover previously unknown trends, anomalies and correlations such as the famed ‘beer and diapers’ correlation (Diapers, Beer, and data science in retail). Going back to the strawberries, assuming that our farmer was a large conglomerate like Cargill, then all of the data above would be sitting ready for analysis in the warehouse so questions such as this could be answered with relative ease: What is the best time to harvest strawberries to get the highest market price? Given certain soil conditions and rainfall patterns at a location, what are the highest yielding strawberry breeds that we should grow?
Data Science
A combination of mathematics, statistics, programming, the context of the problem being solved, ingenious ways of capturing data that may not be being captured right now plus the ability to look at things ‘differently’ (like this Why UPS Trucks Don’t Turn Left ) and of course the significant and necessary activity of cleansing, preparing and aligning the data. So in the strawberry industry we’re going to be building some models that tell us when the optimal time is to sell, which gives us the time to harvest which gives us a combination of breeds to plant at various times to maximize overall yield. We might be short of consumer demand data – so maybe we figure out that when strawberry recipes are published online or on television, then demand goes up – and Tweets and Instagram or Facebook likes provide an indicator of demand. Then we need to align demand data up with market price to give us the final insights and maybe to create a way to drive up demand by promoting certain social media activity.
Machine Learning
This is one of the tools used by data scientist, where a model is created that mathematically describes a certain process and its outcomes, then the model provides recommendations and monitors the results once those recommendations are implemented and uses the results to improve the model. When Google provides a set of results for the search term “strawberry” people might click on the first 3 entries and ignore the 4th one – over time, that 4th entry will not appear as high in the results because the machine is learning what users are responding to. Applied to the farm, when the system creates recommendations for which breeds of strawberry to plant, and collects the results on the yeilds for each berry under various soil and weather conditions, machine learning will allow it to build a model that can make a better set of recommendations for the next growing season.
I am adding this next one because there seems to be some popular misconceptions as to what this means. My belief is that ‘predictive’ is much overused and hyped.
Predictive Analytics
Creating a quantitative model that allows an outcome to be predicted based on as much historical information as can be gathered. In this input data, there will be multiple variables to consider, some of which may be significant and others less significant in determining the outcome. The predictive model determines what signals in the data can be used to make an accurate prediction. The models become useful if there are certain variables than can be changed that will increase chances of a desired outcome. So what might be useful for our strawberry farmer to want to predict? Let’s go back to the commercial strawberry grower who is selling product to grocery retailers and food manufacturers – the supply deals are in tens and hundreds of thousands of dollars and there is a large salesforce. How can they predict whether a deal is likely to close or not? To begin with, they could look at the history of that company and the quantities and frequencies of produce purchased over time, the most recent purchases being stronger indicators. They could then look at the salesperson’s history of selling that product to those types of companies. Those are the obvious indicators. Less obvious ones would be the what competing growers are also bidding for the contract, perhaps certain competitors always win because they always undercut. How many visits the rep has paid to the prospective client over the year, how many emails and phone calls. How many product complaints has the prospective client made regarding product quality? Have all our deliveries been the correct quantity, delivered on time? All of these variables may contribute to the next deal being closed. If there is enough historical data, we can build a model that will predict that a deal will close or not. We can use a sample of the historic data set aside to test if the model works. If we are confident, then we can use it to predict the next deal.
For more information about MoData offerings click here


