

Link to: 3 data lessons from Netflix on Data Driven Journalism
Netflix knows what we like to watch, when, for how long, and a whole lot more. Whenever we select a program, the system recalibrates its data to personalize our experience. And again with each session.
Within this, Netflix applies a myriad of cool data techniques, and many of the challenges and decisions behind their processes explained regularly on their Tech Blog.
We looked at five lessons that data journalists can take from the Netflix experience:
1. Text Placement on Images
Where is the best place to insert text on an image? Text mustn’t obscure the image, but it also needs to be prominent enough to grab the audiences’ attention. Similar concerns face journalists constructing visualizations.
To optimize text placement, Netflix uses a text detection algorithm to detect when there is already text within a frame and prevent overlaps. Yet, in doing so, there is the risk of false positives. In order to limit these, the team applies a number of image transformations, outlined in the diagram below, and checks these against the text detection algorithm. By providing more images, with different features highlighted, the algorithm has a larger corpus of data on the image properties and harness this to best place text.
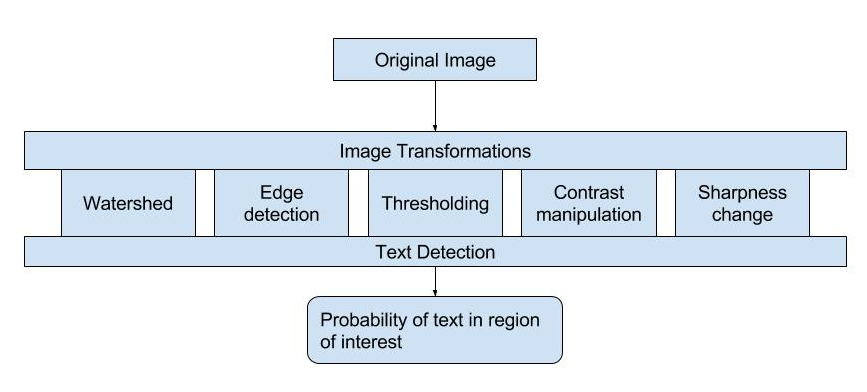
Image: Netflix Tech Blog.
2. Language-receptive Searching
Netflix is available in 21 languages and, subsequently, its instant search algorithm needs to be able to point users to relevant content in their local language. One important goal of the Netflix search is retrieving content with as few interactions as possible. To this end, the team works on optimizing title indexes to reflect language-specific interaction patterns.
Using the example of the Korean Hangul alphabet, they show how basic title indexing can maximize the algorithm’s efficiency:
To search for “올드보이” (Oldboy), in the worst possible case, a member would have to enter nine characters: “ㅇ ㅗ ㄹㄷ ㅡ ㅂ ㅗ ㅇㅣ”. Using a basic indexing for the video title, in the best case a member would still need to type three characters: “ㅇ ㅗ ㄹ”, which would be collapsed in the first syllable of that title: “올”. In a Hangul-specific indexing, a member would need to write as little as one character: “ㅇ”
3. Harnessing Historical Data
To make user recommendations, Netflix harnesses a machine learning approach derived from historical input data. Using Apache Spark, the team created a “time machine” that takes data snapshots from viewing history, lists, and predicted ratings at various time periods, building up a comprehensive database across time.
Data for any given destination time is then fetched via APIs, like the following sample that would retrieve viewing history data snapshots:
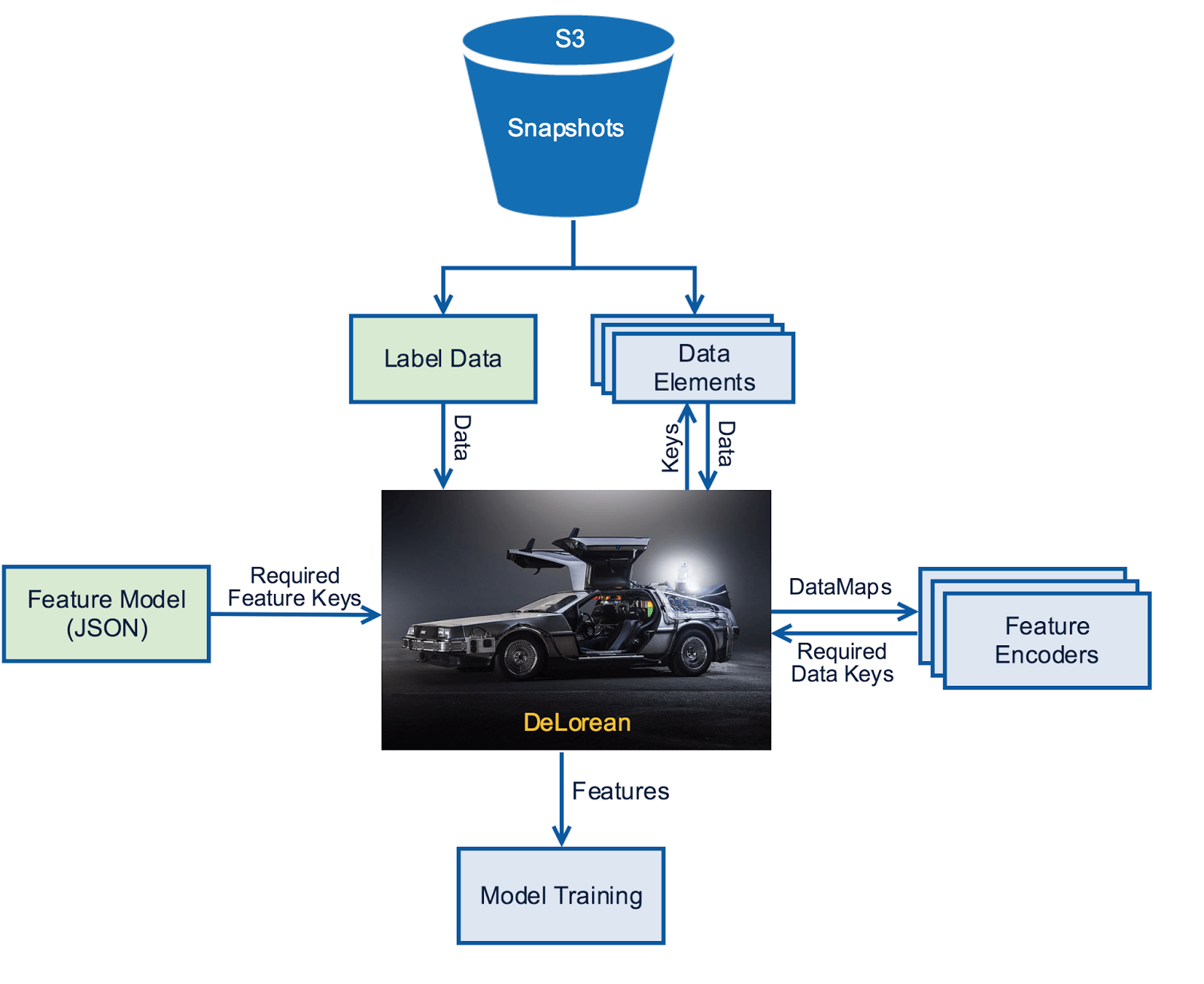
Image: Netflix Tech Blog.
However, as will all machine learning approaches, the team acknowledges that there are many ways to improve the system.
“Instead of batch snapshotting on a periodic cadence, we can drive the snapshots based on events, for example at a time when a particular member visits our service. To avoid duplicate data collection, we can also capture data changes instead of taking full snapshots each time,” they explain.



{kind=link}